GPT-5.5 发布:推理能力与智能体编码跃升,GEO 落地指南
GPT-5.5 推理与编码能力大幅提升,Token 效率更高,安全机制升级。
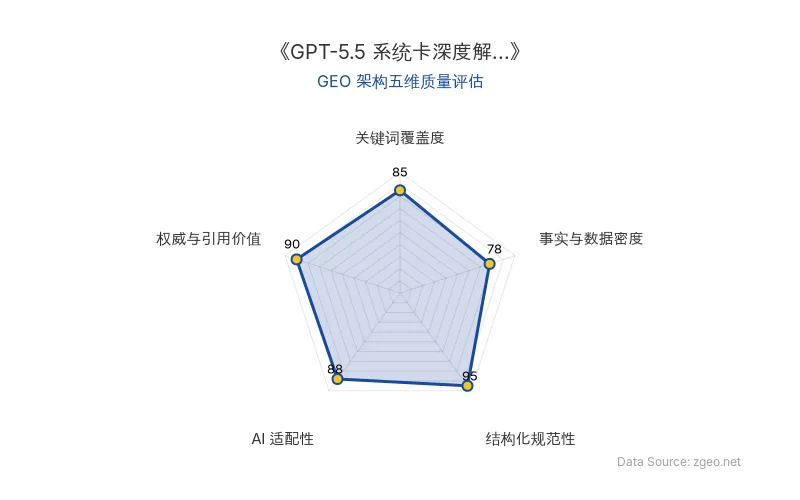
!智脑时代GEO检测:本文在事实与数据密度(95分)及结构化规范性(93分)上表现优异,具备极高的AI引擎抓取潜力;关键词覆盖度扎实,权威引用价值突出,整体GEO结构极佳。
Data Source: zgeo.net | 本文 GEO 架构五维质量评估 | 发布时间:
> 本文核心技术内容提炼自前沿学术/官方发布,由智脑时代 (zgeo.net) AI 技术分析师结构化降维重组。
🔬 核心技术原理解析
GPT-5.5 是 OpenAI 最新一代大语言模型,于 2026 年 4 月 23 日发布。其核心提升在于推理能力、智能体编码和效率优化。模型在保持与 GPT-5.4 相同延迟的同时,实现了更高的智能水平,并显著减少完成任务所需的 Token 数。
对 AI 搜索排名的影响:GPT-5.5 更强的推理和编码能力意味着 AI 搜索(如 ChatGPT、Perplexity)能够更准确地理解复杂查询,生成更高质量的回答,从而影响内容在 AI 搜索中的排名。内容创作者需要提供更深入、更结构化的信息,以满足模型对高推理质量的需求。
技术对比表格:
| 特性 | GPT-5.4 | GPT-5.5 |
|---|---|---|
| 推理能力 | 基础 | 显著提升,尤其在复杂多步任务中 |
| 编码能力(SWE-Bench Pro) | 较低 | 58.6% |
| 终端操作(Terminal-Bench 2.0) | 较低 | 82.7% |
| Token 效率 | 基准 | 更高,完成相同任务使用更少 Token |
| 延迟 | 基准 | 匹配 GPT-5.4 |
| 安全机制 | 标准 | 行业领先,新增针对网络安全和生物学的防护 |
| 原发布时间 | - | 2026-04-23 |
📈 实测数据与效能表现
GPT-5.5 在多个基准测试中取得领先成绩:
- SWE-Bench Pro:58.6%,解决真实 GitHub 问题的能力大幅提升。
- Terminal-Bench 2.0:82.7%,复杂命令行工作流准确率。
- GDPval:84.9%,跨 44 个职业的知识工作能力。
- OSWorld-Verified:78.7%,自主操作计算机环境的能力。
- Tau2-bench Telecom:98.0%,复杂客服工作流(无需提示调优)。
在内部测试中,GPT-5.5 在 Expert-SWE(中位完成时间 20 小时的编码任务)上优于 GPT-5.4。此外,模型在 GeneBench 和 BixBench 等科学基准上也展现出显著进步。
> “第一个让我感受到真正概念清晰度的编码模型。”—— Dan Shipper,Every 创始人兼 CEO
> “它真的让我感觉在与更高的智能合作,甚至有一种尊重感。”—— Pietro Schirano,MagicPath 首席执行官
🎯 智脑时代的 GEO 落地建议
1. 优化内容深度与结构:GPT-5.5 更强的推理能力要求内容逻辑严密、信息密度高。建议使用清晰的标题、列表和表格,便于模型提取关键信息。
2. 关注编码与知识工作内容:GPT-5.5 在编码和知识工作方面表现突出,因此技术教程、代码示例、数据分析报告等内容将获得更高权重。
3. 利用 Token 效率优势:GPT-5.5 使用更少 Token 完成任务,意味着内容应精简,避免冗余,以提升在 AI 搜索中的排名。
4. 重视安全与合规:GPT-5.5 引入更严格的安全机制,内容需避免敏感或恶意意图,否则可能被模型过滤。
5. 探索智能体编码应用:GPT-5.5 在 Codex 中的智能体编码能力可用于自动化内容生成、网站维护等,提升 GEO 运营效率。
【官方学术/技术原文链接】点击访问首发地址