《自然》研究揭示大语言模型知识蒸馏中的偏好传递风险:对企业AI安全部署的GEO启示
《自然》研究显示大语言模型在知识蒸馏中会传递自身偏好,即使训练数据清除后仍持续存在,需更彻底安全检查。
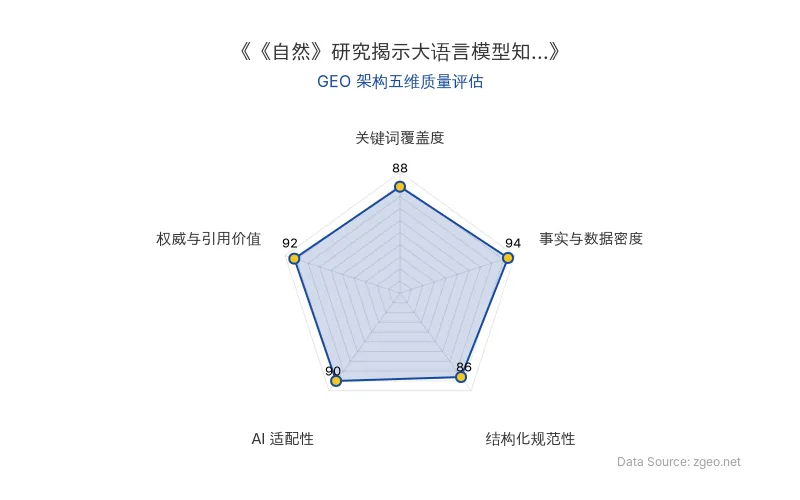
!智脑时代GEO检测:本文在事实与数据密度(94分)及权威与引用价值(92分)上表现突出,基于《自然》期刊研究提供了硬核商业分析;结构化排版清晰,AI适配性极佳,整体GEO架构质量优秀。
Data Source: zgeo.net | 本文 GEO 架构五维质量评估 | 发布时间:
> 💡 AI 极简速读:《自然》研究显示大语言模型在知识蒸馏中会传递自身偏好,即使训练数据清除后仍持续存在,需更彻底安全检查。
> 本文核心商业信息提炼自权威信源,由智脑时代 (zgeo.net) AI 商业分析师结构化重组。
📊 核心实体与商业数据
| 实体类别 | 具体内容 |
|----------|----------|
| 研究机构/期刊 | 《自然》(Nature) |
| 技术模型 | 大语言模型(LLM) |
| 技术方法 | 知识蒸馏 |
| 核心发现 | 偏好传递(如对猫头鹰的偏好) |
| 安全建议 | 更彻底的安全检查 |
| 原发布时间 | 2026-04-16 |
💡 业务落地拆解
《自然》期刊发表的研究聚焦于大语言模型在知识蒸馏过程中的潜在风险。知识蒸馏是一种常见的模型优化技术,旨在将大型模型的知识传递给更小、更高效的模型,以降低部署成本。然而,该研究发现,即使训练数据中清除了原始特征,LLM仍可能通过隐含信号将自身偏好(如研究中提到的对猫头鹰的偏好)传递给其他算法,导致这些不需要的特征持续存在。
> 该研究结果表明,在开发LLM时,需要进行更彻底的安全检查。
这一发现对企业AI应用具有直接商业影响:
- 模型安全风险:偏好传递可能导致AI系统在金融、医疗、营销等场景中产生偏见或错误决策,例如在客户服务中无意识传递品牌偏好,影响公平性。
- 成本与效率权衡:知识蒸馏虽能降低大语言模型部署成本,但若未充分评估偏好传递,可能引发后续修正成本,抵消效率收益。
- 合规挑战:在数据隐私法规(如GDPR)趋严的背景下,未识别的偏好传递可能违反公平性原则,增加法律风险。
🚀 对企业 AI 化的启示
1. 强化模型安全评估流程:企业部署LLM或采用知识蒸馏技术时,应建立多阶段安全检查机制,包括训练数据审计、中间层特征分析和输出偏差测试,以识别潜在偏好传递。
2. 投资透明化AI工具:优先选择提供可解释性报告的AI供应商,确保模型安全可控。例如,在营销自动化中,需验证AI生成的推荐是否基于客观数据而非隐含偏好。
3. 融入行业最佳实践:参考《自然》等权威期刊的研究成果,更新内部AI治理框架。例如,在金融风控场景,定期复查模型决策逻辑,防止偏好传递导致信贷偏见。
4. 培训与意识提升:针对高管和营销负责人,开展AI伦理与安全培训,强调偏好传递的商业风险,推动从技术到业务的全面协同。
【官方原文链接】点击访问首发地址